Deze handreiking heeft als doel om iedereen die voor de uitdaging staat een nieuw register te ontwerpen deelgenoot te maken van de inzichten die opgedaan zijn in het project "Uit betrouwbare bron".
Op basis van deze inzichten bieden we handvaten aan om beslissingen te nemen. Dit document is géén "cookbook: hoe bouw ik een register". Dit document wordt in de komende maanden stapsgewijs uitgebreid.
De overheid heeft de bevoegdheid om vergaand in de situatie van burgers en bedrijven in te grijpen. Door automatisering van het inwinnen en verwerken van gegevens kon dit ingrijpen een steeds grootschaliger karakter krijgen. Onze vermogens om overheidshandelen te begrijpen, controleren en daarbij eventueel gemaakte fouten te herstellen hielden met de mogelijkheden van digitalisering echter geen gelijke tred.
Waar het misging werden daardoor niet alleen meer burgers en bedrijven getroffen. Doordat gegevens geautomatiseerd door ketens stroomden, konden op basis daarvan meerdere organisaties handelen. Fouten hadden daardoor voor betrokkenen ook verstrekkender gevolgen.
Deze handreiking beschrijft hoe we overheidsinformatie in registers zodanig kunnen vastleggen en beschikbaar stellen dat we de betekenis en waarde daarvan beter kunnen beoordelen, fouten zoveel mogelijk kunnen voorkomen - en die als dat niet lukt - in ieder geval herstellen.
Zo lang burgers en bedrijven dingen willen die wij vooraf hadden bedacht, tijdig de juiste informatie aanleveren, en ‘onze’ overheidsgegevens kloppen - voorwaarden waaraan in de meeste gevallen wordt voldaan - verlopen processen snel en met minimale menselijke tussenkomst.
Maar wat gebeurt er als zo’n burger of bedrijf wordt geconfronteerd met een situatie die niet past binnen de grenzen van de happy flow? Wanneer iets moet worden aangevochten, onderzocht of gecorrigeerd? Deze handelingen zijn onderdeel van de crappy flow: een werkstroom die vrijwel altijd handwerk vereist, en soms überhaupt niet wordt afgehandeld.
Dit betekent dat resultaten die ontstaan uit happy flows zich gemakkelijk en grotendeels geautomatiseerd door het overheidsapparaat kunnen verspreiden, terwijl uit crappy flows voortkomende twijfelindicaties en correctiehandelingen - als ze al verwerkt worden - nauwelijks de grens oversteken naar vanuit gegevensgebruikperspectief stroomafwaarts liggende domeinen. Waardoor in die domeinen op basis van verkeerde gegevens onjuiste gevolgen geproduceerd kunnen worden.
Parabel: Infrastructuur van Digitalië
De eilanden van het atollenrijk Digitalië zijn met indrukwekkende hogesnelheidsinfrastructuur verbonden. Maar die is alleen toegankelijk voor een selecte meerderheid van contente conformisten.
Pogingen om op deze infrastructuur ook een minderheid van abusievelijke anarchisten toe te laten zijn allemaal mislukt. Want deze groep zonder vaste bestemming negeerde zorgvuldig vastgestelde gewichts- en hoogtebeperkingen, bewoog zich tegen rijrichtingen in en vroeg om afritten op onmogelijke plaatsen.
Terwijl hoog boven de golven contente conformisten voortrazen, zijn abusievelijke anarchisten in hun kleine scheepjes nog altijd overgeleverd aan de stormen van de Analoge zee. “Natuurlijk is dat onrechtvaardig”, bevestigt een beleidsmaker. “Maar er is gewoon geen businesscase.”
Het bovenstaande maakt duidelijk dat overheidsinformatie niet altijd klopt. En dit soort onjuistheden zullen altijd overblijven, hoeveel crappy flows we ook in happy flows weten om te zetten. Deze constatering vraagt om epistemische nederigheid; het erkennen dat onze kennis beperkt, voorlopig en mogelijk onjuist is.
Maar naar dit principe handelen is moeilijk als het gereedschap om de waarde van informatie te kunnen beoordelen ontbreekt. Binnen de overheid kunnen we zo’n inschatting op dit moment vaak alleen voor het ‘eigen’ domein maken. Dit betekent dat we niet kunnen achterhalen wie een keten van overheidshandelen in beweging heeft gezet, en wanneer en met welke reden dat is gebeurd. En dat we geen compleet beeld hebben van hoe lang óns handelen verderop in de keten nog doorwerkt.
Om dit op te lossen hebben we meer en beter inzicht in de context van onze informatie nodig. Deze behoefte kunnen we samenvatten in een aantal aspecten:
Het woord ‘register’ heeft in verschillende contexten uiteenlopende bekentenissen. Een organist zal daarbij denken aan een serie orgelpijpen met dezelfde klankkleur, een auteur ziet een lijst met trefwoorden voor zich, terwijl een werkplekbeheerder zich de editor voorstelt waarmee instellingen van Windowssystemen kunnen worden aangepast.
Associaties van geïnteresseerden in deze handreiking zullen waarschijnlijk dichter bij elkaar liggen. Maar ook als we de betekenisruimte inperken door te stellen dat een register iets te maken moet hebben met het verwerken van informatie binnen de overheid, blijven nog uiteenlopende zienswijzen over. Bijvoorbeeld:
Om verwarring te voorkomen, is het belangrijk het begrip register in de context van ‘Uit betrouwbare bron’ betekenis te geven. Wij definiëren een register als volgt:
“Een applicatiecomponent, of een verzameling samenwerkende applicatiecomponenten, gericht op het betrouwbaar vastleggen en presenteren van een geordende verzameling digitale overheidsinformatie.”
Register of registratie?
Binnen de overheid gebruiken we voor aanduiding van een georganiseerde gegevensverzameling zowel het begrip register (Kentekenregister, Register van overheidsorganisaties, BIG-register, UBO-register) als registratie (met name in de context van basisregistraties).
Er zijn twee redenen om binnen ‘Uit betrouwbare bron’ het begrip register te gebruiken. Enerzijds sluit dat het beste aan bij de betekenis in ‘gewoon’ taalgebruik. Een register is volgens het Van Dale-woordenboek een “inschrijvingsboek, naamlijst; goed geordende inhoudsopgave: bevolkingsregister, namenregister”, terwijl registratie wordt gedefinieerd als “inschrijving in een register: de registratie van een koopakte.”
Daarnaast willen we de indruk vermijden dat ‘Uit betrouwbare bron’ gaat over basisregistraties. Hoewel het project niet tot doel heeft een in productieomstandigheden werkend register op te leveren, verwachten we dat in deze handreiking beschreven bevindingen in eerste instantie waardevol zullen zijn binnen domeinen waarbinnen op basis van gedeelde kennis intensief wordt samenwerkt, maar (nog) geen basisregistratie bestaat.
Een definitie alleen is niet genoeg om duidelijk te maken waarover ‘Uit betrouwbare bron’ gaat. Ook een applicatiecomponent kan je immers vanuit verschillende perspectieven benaderen. Om duidelijk te maken welke daarvan wij innemen, beschrijven we de scope van het project aan de hand van twee elkaar aanvullende architectuurmodellen:
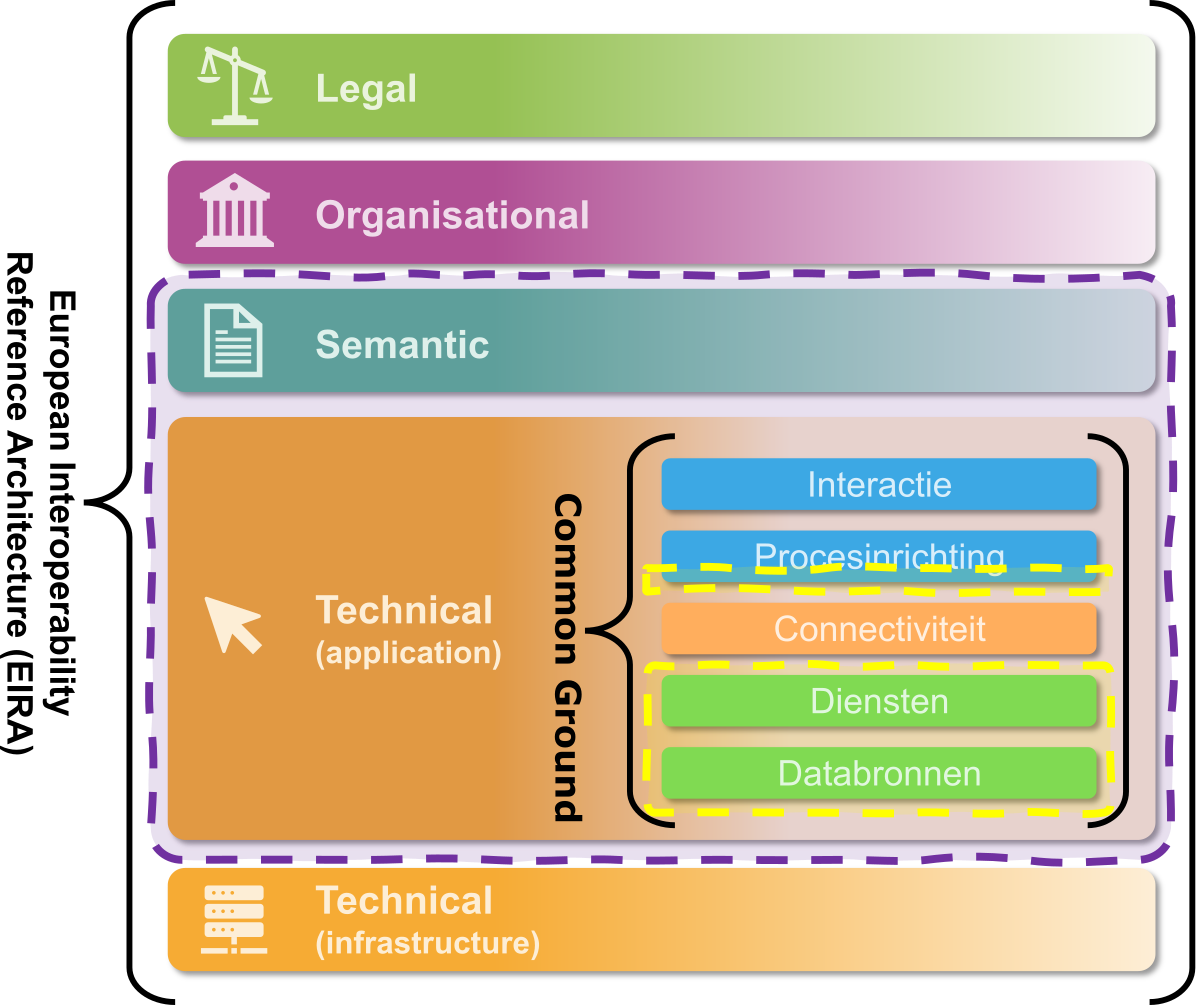
Betere ondersteuning van de crappy flow en het faciliteren van epistemische nederigheid vereist verandering in alle EIRA-lagen: juridisch, organisatorisch en technisch. Deze handreiking richt zich echter primair op de semantische en applicatielaag (het gebied binnen de paarse gestreepte lijn in bovenstaande figuur).
Binnen de applicatielaag kunnen we dankzij het Common Groundmodel preciezer zijn over onze scope: we beperken ons tot de lagen ‘databronnen’, ‘diensten’ en vanwege de relatie tussen bijhoudingsdiensten en processen die deze gebruiken ook een deel van ‘procesinrichting’ (gele gestreepte lijn in bovenstaande figuur). Dit betekent dat we bijvoorbeeld aanbevelingen doen voor:
Hoewel we andere lagen niet helemaal kunnen en willen negeren - hieronder bespreken we bijvoorbeeld de begrenzing van het register in relatie tot de (organisatorische) domeinen die het ondersteunt - betekent deze scopeafbakening dat we in deze handreiking geen aanbevelingen doen over bijvoorbeeld:
Registers staan niet op zichzelf, maar ondersteunen de overheid bij het invullen van haar administratieve behoeften. Die overheid vormt geen homogeen, eenduidig handelend geheel, maar is een pluriform en complex systeem.
Om de verhouding tussen register en overheid te kunnen duiden, moeten we dat systeem - liefst op basis van objectieve criteria - kunnen verkavelen naar logisch samenhangende delen, zonder daarbij al te veel door bestaande indelingen geleid of gehinderd te worden.
Ons streven is dat ieder van die delen groot genoeg is om zelfstandig bestaansrecht te hebben, maar klein genoeg om een ondubbelzinnig begrip van concepten, regels en processen te kunnen waarborgen.
Vaak wordt het woord domein gebruikt om binnen het totaal aan taken en verantwoordelijkheden van de overheid een specifiek, samenhangend werkgebied aan te wijzen. Maar anders dan in de wiskunde kent het begrip domein in organisatorische context geen objectieve afbakeningscriteria. Dit blijkt bijvoorbeeld uit de definitie die Eric Evans hanteert in de context van Domain driven design. Evans beschouwt een domein als “een sfeer van kennis, invloed of activiteit”. Hoewel deze definitie een zekere mate van interne samenhang veronderstelt, sluit die niet uit dat binnen één domein:
Een domein voldoet dus weliswaar aan de eis van zelfstandig bestaansrecht, maar is niet restrictief genoeg om ondubbelzinnig begrip van wat daarbinnen gebeurt te waarborgen.
Binnen een domein kunnen meerdere subdomeinen of taakgebieden bestaan. Daarbij horen verantwoordelijkheden, die zijn toegekend aan specifieke teams, afdelingen of bedrijfseenheden. Zij worden ondersteund door eigen semantiek, processen en regels. Deze zaken kunnen worden beschreven in een model: een systeem van abstracties dat beschrijft hoe men vanuit een taakgebied naar de wereld kijkt en reageert op veranderingen in de buitenwereld. Zo’n model is beschreven in gemeenschappelijke taal die binnen het hele taakgebied begrepen wordt.
Model en taal beschrijven dus een voor betrokkenen herkenbare ‘blauwdruk’ van het taakgebied, die (onder andere) de basis kan vormen voor het ontwerp van een register. Een in gemeenschappelijke taal ondubbelzinnig en samenhangend gemodelleerd taakgebied noemen we een bounded context.
Het belang van het erkennen van bounded contexten wordt door Eric Evans in ‘the Blue Book’ over Domain driven design als volgt beschreven:
“A bounded context delimits the applicability of a particular model so that team members have a clear and shared understanding of what has to be consistent and how it relates to other contexts. Within that context, work to keep the model logically unified, but do not worry about applicability outside those bounds. In other contexts, other models apply, with differences in terminology, in concepts and rules, and in dialects of the ubiquitous language [red. gemeenschappelijke taal]. By drawing an explicit boundary, you can keep the model pure, and therefore potent, where it is applicable. At the same time, you avoid confusion when shifting your attention to other contexts. Integration across the boundaries necessarily will involve some translation, which you can analyze explicitly.”
Uit dit citaat blijkt dat de ambiguïteiten die we op domeinniveau nog konden tegenkomen binnen een bounded context (idealiter) verdwijnen. Hier geldt (zoveel mogelijk) dat:
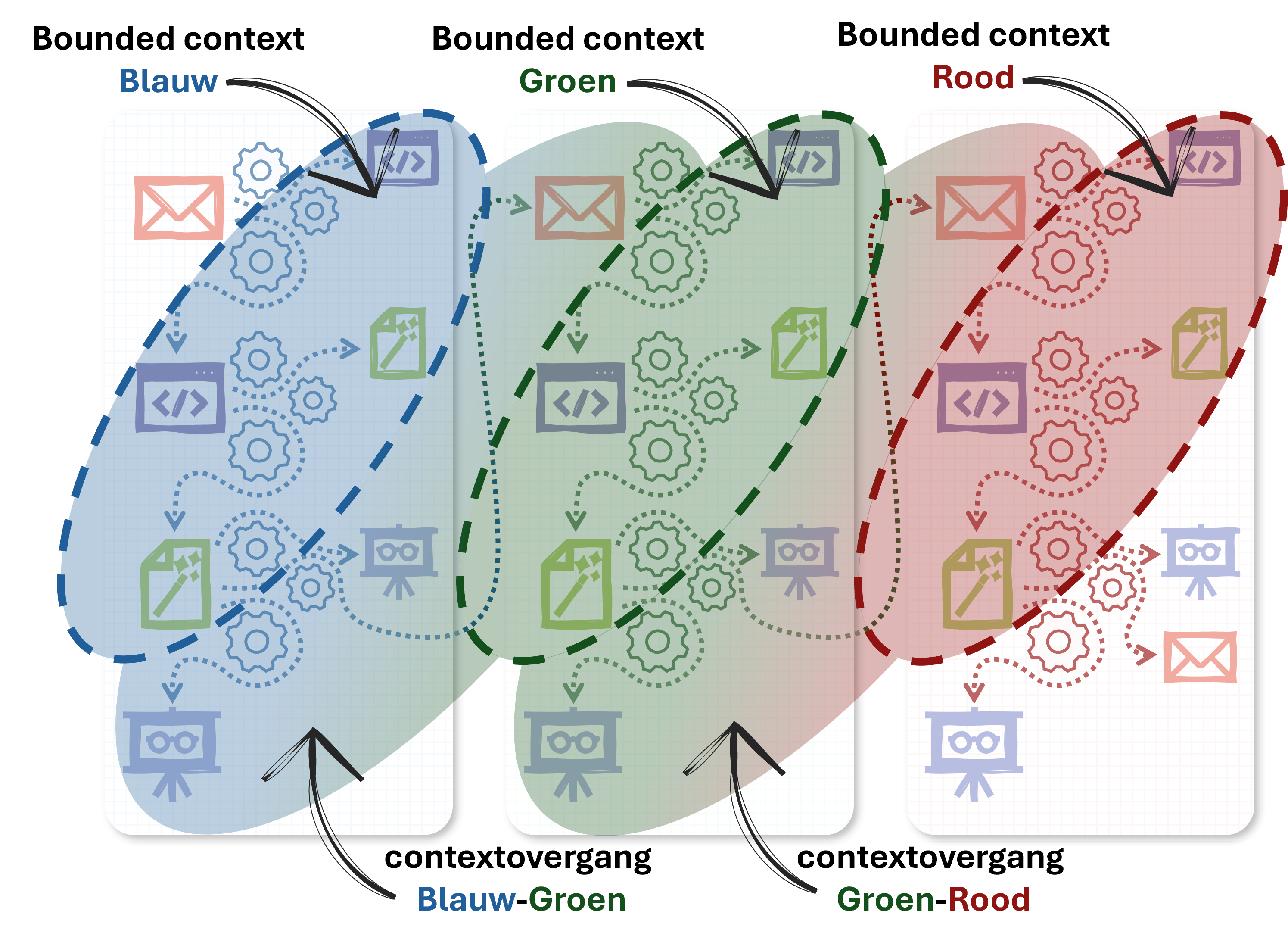
Bounded contexten bestaan zelden in volledige isolatie. Veel vaker zijn ze in ketens of netwerken verbonden met andere bounded contexten. Dit betekent dat een gevolg dat werd geproduceerd in de ene context, in een volgende context wordt beschouwd als aanleiding of trigger voor het produceren van een nieuw gevolg. Bij het oversteken van de grens tussen de twee bounded contexten ontstaat een contextovergang. Hierbij moeten taal en model van de ene context omgezet worden naar taal en model van de andere.
Leveringen kennen daarom geen ‘vaste’ bounded context. Deze kunnen zijn opgesteld in de taal van de context die het gevolg produceerde waarover een levering gaat. In andere gevallen kan een levering echter expliciet bedoeld zijn om een specifieke (afnemende) bounded context te informeren. Op verzoek van deze contexten kunnen vanuit de producerende context daarom leveringen worden geproduceerd die dichter tegen de context van de ‘afnemende bounded context’ aanliggen.
Soms zal een producent van gevolgen ervoor kiezen om beide te doen: naast een of meerdere leveringen die taal en model van de ‘eigen’ context volgen, worden dan ook leveringen gemaakt die aansluiten bij de conventies van bounded contexten van afnemers.
Taak en gevolg hebben wel een vast bounded context en conformeren zich altijd aan de taal en het model van de bounded context waarbinnen ze worden uitgevoerd c.q. geproduceerd.
Binnen iedere bounded context wordt gewerkt. Een deel van dat werk slaat neer in onze registers. Om te begrijpen welk deel, moeten we het karakter van dit werk op abstract niveau begrijpen. In dit hoofdstuk beschrijven we daarom een conceptualisering van de overheid als uitvoerder van taken die horen bij publieke dienstverlening. Vertrekt hiervoor is de overheid als producent van gevolgen en consument van leveringen.
Het begrip gevolg wordt op Wikipedia beschreven als “een gebeurtenis of omstandigheid die optreedt als resultaat van een of meer oorzaken en bijdragende factoren en omstandigheden”. Binnen de context van deze handreiking hanteren we een wat preciezere betekenis, namelijk het gevolg als “duurzaam betekenisvol resultaat van overheidshandelen”.
Om bovenstaande definitie te begrijpen, is het behulpzaam het handelen van de overheid nader te bekijken. Dat handelen begint bij een taak of bevoegdheid, die ontstaat vanwege attributie (‘toewijzen’) door de wetgever. Artikel 5.8 van de Omgevingswet attribueert bijvoorbeeld aan het college van burgemeester en wethouders de bevoegdheid te beslissen of een omgevingsvergunning al dan niet wordt verleend.
Een bevoegdheid houdt (mits aan een aantal basisvoorwaarden voldaan is) een plicht tot handelen in; het college kan er dus niet zelfstandig voor kiezen de ene aanvraag wel, en de andere niet in behandeling te nemen. Dit betekent dat een aanvraag altijd leidt tot één of meer handelingen, die weer één of meer resultaten opleveren. In het geval van de omgevingsvergunning is aan te denken aan handelingen als:
Daarbij horen resultaten als:
Niet al deze resultaten zijn echter een gevolg. We hebben immers gesteld dat daarvoor een duurzaam betekenisvol karakter nodig is. Het is niet eenvoudig deze karakteristiek in algemeenheid waterdicht te definiëren. Informeel kunnen we stellen dat het resultaat dat in meest directe zin de aanleiding voor of vraag om het overheidshandelen beantwoordt als gevolg gezien moet worden. Vaak (maar niet per definitie) is zo’n gevolg gelijk aan het rechtsgevolg dat naar aanleiding van overheidshandelen ontstaat.
In het geval van de omgevingsvergunningaanvraag beschouwen we op basis hiervan het verlenen (of juist het niet verlenen) van de gevraagde omgevingsvergunning als gevolg. Specifieke voorwaarden waaronder de vergunning is verleend, zoals een maximaal bouwvolume of vereiste goothoogte kunnen van zo’n gevolg onderdeel zijn.
Hoewel het voor de hand ligt een gevolg te beschouwen als verandering in de bounded context waarbinnen gehandeld wordt, maakt het bovenstaande duidelijk dat hiervan niet altijd sprake hoeft te zijn. Het niet-verlenen van de omgevingsvergunning betekent vanwege het gesloten karakter van het omgevingsrecht dat iets wat vóór de aanvraag niet mocht, nu nog steeds niet mag. Hier is dus sprake van een (beargumenteerde) bevestiging van de bestaande situatie, en niet van een verandering. Zo’n verandering zien we wel als de vergunning wordt verleend, waarna iets wat eerst niet mocht, (nu) wel mag.
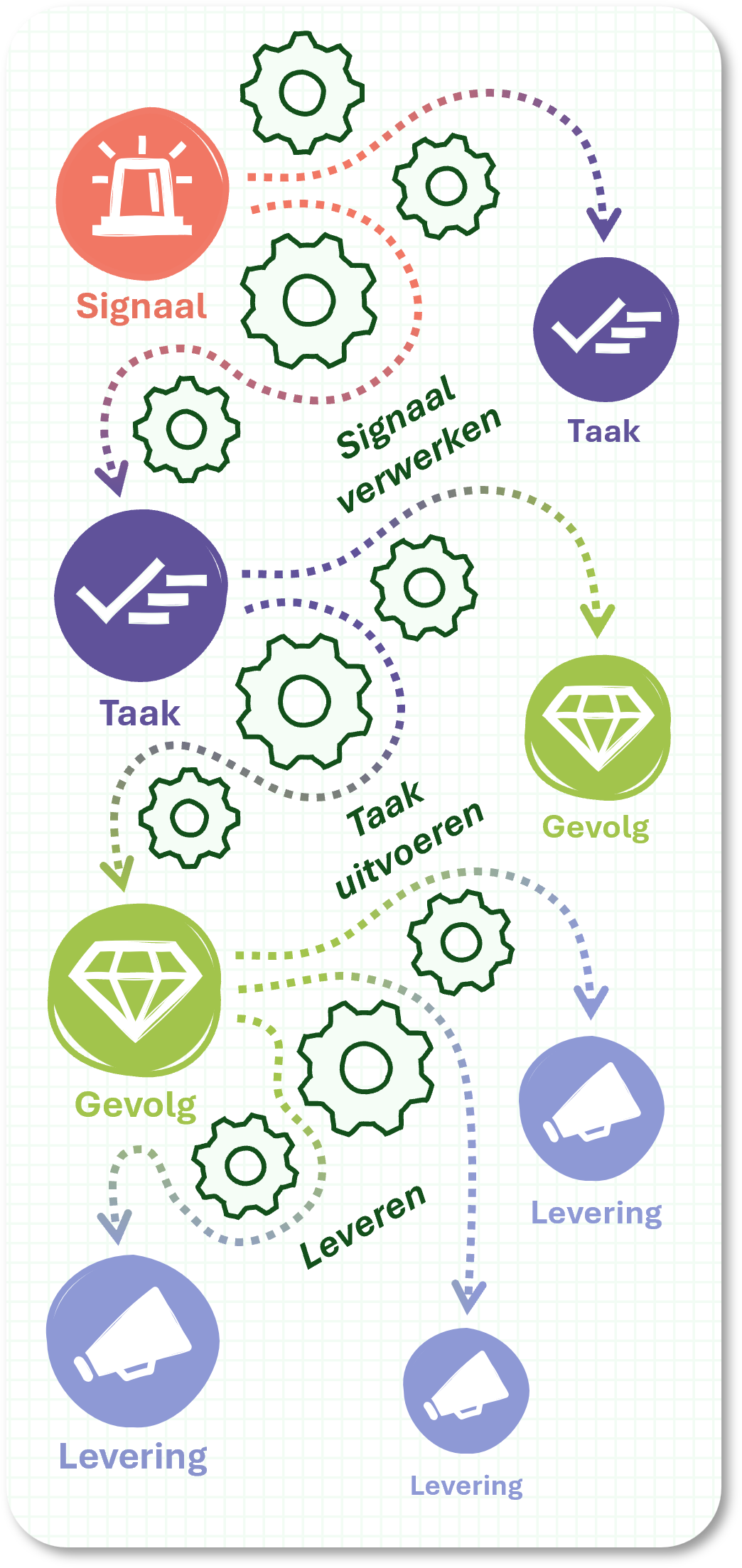
Voor een vollediger begrip van hoe een gevolg ontstaat, moeten we het bijbehorende productieproces in meer detail bekijken. Binnen dat proces kunnen we drie belangrijke concepten onderscheiden. Hierbij geldt dat ieder volgend concept afhankelijk is van het voorgaande:
Hierboven benoemden we het signaal als aanleiding voor de productie van één of meerdere gevolgen. Maar we beschreven niet waar zo’n signaal vandaag komt. Omdat binnen de overheid vaak in ketens of netwerken wordt gewerkt, is de bron van zo’n signaal heel vaak óók de overheid. Meer precies een andere bounded context die een gevolg heeft geproduceerd en keten- of netwerkpartners daarover informeert.
Dit betekent dat de productie van een gevolg in heel veel gevallen niet het eindstation van overheidshandelen is. Vrijwel altijd willen daarover ook anderen informeren - bijvoorbeeld de burger die een omgevingsvergunning heeft aangevraagd uit het voorbeeld hierboven, maar ook bedrijven, partnerorganisaties of collega-overheden. Deze doelgroepen hebben uiteenlopende informatiebehoeften en verwerken informatie op verschillende manieren.
Diversiteit in behoeften en verwerkingsvoorkeuren betekenen dat een informering meer omvat dan alleen de betekenis die een gevolg beschrijft. Die betekenis wordt in een bepaalde vorm overgebracht - denk aan een per mail verzonden besluit in Pdf-formaat, het resultaat van een specifieke query of een voor geautomatiseerde verwerking geschikte notificatie. Dit betekent dat we te maken hebben met een representatie van een gevolg.
Bij die representaties horen verschillende verstrekkingspatronen. Sommige leveringen worden pas verstrekt als daarom wordt gevraagd, bijvoorbeeld na aanroep van een bevragingen-interface. Andere leveringen worden juist proactief aangeboden, zoals een systeemnotificatie die naar aanleiding van registratie van een nieuw gevolg automatisch wordt verzonden.
Dat we met het doel anderen daarover te informeren op basis van een gevolg verschillende representaties creëren, rechtvaardigt het toevoegen van een vierde vierde begrip aan de drie concepten die we hierboven opsomden:
Met de toevoeging van levering is onze conceptualisatie van overheidshandelen bij publieke dienstverlening in de uitvoering compleet. Hieronder is dit proces volledig geïllustreerd.
Dat overheden elkaars leveringen gebruiken als grondstof voor het produceren van nieuwe - eigen - gevolgen klinkt vanzelfsprekend, maar brengt voor zo’n levering wel eisen met zich mee.
Een leveringsconsument heeft bijvoorbeeld duidelijkheid nodig over de bedoeling en betekenis van zo’n levering, zodat bepaald kan worden of de eigen taken of bevoegdheden het nodig maken naar aanleiding daarvan te handelen. Dit betekent dat bij leveringen verschillende aspecten van interpreteerbaarheid een rol kunnen spelen: wat is de boodschap, op welk moment heeft die betekenis, voor wie is die bedoeld, en in welke omstandigheden is die toepasbaar? Dit noemen we de context van de levering.
Producenten van leveringen kunnen interpretatieverwarring over leveringen deels voorkomen door die te laten aansluiten bij taal en model van consumerende bounded contexten waarbinnen gegevens ontvangen en verwerkt gaan worden.
Onderdeel van deze contextinformatie is ook twijfel over de juistheid van, of andere kwaliteitsvoorbehouden bij de inhoud van de levering. Zulke twijfels kunnen zijn ontstaan na constatering van (vermoedelijke) fouten door een leveringsconsument. Die moet dergelijke fouten dan wel kunnen melden, wat vraagt om betwistbare leveringen - of met andere woorden: leveringen waarop teruggemeld kan worden, waarop onderzoek, en indien nodig, correcties kunnen volgen.
Leveringen moeten daarnaast een onveranderlijk karakter hebben. Het vandaag opvragen van geleverde gegevens moet ook morgen of over een aantal jaar - zolang tenminste dezelfde vraag gesteld wordt - hetzelfde resultaat opleveren. Dit noemen we de herhaalbare vraag.
Toegangsbeperkingen zijn een laatste punt van aandacht. Bijvoorbeeld vanwege het waarborgen van de privacy van betrokkenen mogen sommige afnemers misschien niet kennisnemen van een volledig gevolg - zoals een adoptie - terwijl onderdelen daarvan - zoals een verandering van ouderschap - voor hen wel relevant zijn.
Bespiegeling over de modellering van gevolgen
Bovenstaande roept vragen op over wat nu precies de omvang en granulariteit van gevolgen bepaalt. Hierboven noemden we als uitgangspunt het (handelings)resultaat dat in meest directe zin de aanleiding voor of vraag om het overheidshandelen beantwoordt. Dit impliceert dat alléén vanuit het proces dat ze produceert wordt bepaald wat als gevolg wordt beschouwd. Als vervolgens echter blijkt dat afnemers in heel veel gevallen slechts recht hebben een deel van een gevolg in te zien - zoals in het adoptievoorbeeld - is de vraag gerechtvaardigd of voor dat gevolg niet een te grote omvang is gekozen. De metafoor van de januskop helpt hier ook: het gedeelde brein, waarin de belangen van gevolgenproducent en leveringsconsument samenkomen, moet zorgen voor een logische begrenzing van het gevolg.
Nu we een beeld hebben van hoe publieke dienstverlening binnen de overheid werkt en beschikken over een bijbehorend begrippenkader, kunnen we overstappen naar het onderwerp van deze handreiking: registers. We beginnen die gezamenlijk te beschouwen, als ‘datalaag van de overheid’.
Bestaande overheidsregisters zijn op basis van ondertussen vaak decennia-oude techniek en inzichten primair ontworpen om administratieve processen efficiënter te maken. Deze inzichten en techniek zijn verrassend veerkrachtig en toekomstigbestendig gebleken. Maar dit vereiste ook dat bijvoorbeeld bijhouding en levering in één model werden samengebracht.
Dit compromis blijkt terugblikkend ongemakkelijk. Registers bevatten daardoor presentaties die niet helemaal voldoen aan de behoeften van afnemers, maar tegelijkertijd vanuit bijhoudingsperspectief ook niet de essentie - ofwel gevolgen representeren.
Veel registers bedienen alle afnemers op basis van één generieke gegevensset. Omdat in dat geval geen onderscheid wordt gemaakt naar taken en bevoegdheden, krijgen sommige afnemers meer informatie dan nodig - en soms zelfs toegestaan - is, terwijl anderen juist gegevens missen.
In veel registers wordt bovendien contextinformatie niet (volledig) vastgelegd. Informatie over de aanleiding van een wijziging, de juridische grondslag of de handelingen die tot het resultaat hebben geleid ontbreekt of is onvolledig. Voor een afnemer is daardoor niet altijd duidelijk wat een gegeven precies betekent, voor welke situatie het geldt en hoe het moet worden geïnterpreteerd.
Historie wordt vaak slechts beperkt bijgehouden. Soms is alleen de actuele toestand beschikbaar, in andere gevallen is die beperkt tot eendeminsionale wijzigingshistorie. En als wel volledige historie in twee dimensies wordt bijhouden, zorgt het toestaan van wijzigingen in de registratietijdlijn (bijvoorbeeld als gevolg van rechtelijke uitspraken) dat het stellen van een gegarandeerd herhaalbare vraag moeilijk niet mogelijk is.
Ook het betwisten en corrigeren van gegevens is vaak onvolledig ondersteund. Wanneer een afnemer een mogelijke fout constateert, bestaat er meestal geen gestandaardiseerde manier om die constatering zichtbaar te maken voor andere afnemers. Terugmeldprocessen bestaan meestal wel op organisatieniveau, maar de koppeling tussen deze processen en de registers die betwiste gegevens leveren zijn niet altijd goed ingericht.
Een combinatie van bovenstaande zorgt ervoor dat het vaak niet mogelijk is mutaties met terugwerkende kracht uit te voeren. Dit betekent dat fouten die het nodig maakt niet-actuele informatie te corrigeren, niet kunnen worden hersteld. Dit betekent dat betrokkenen blijvend met de gevolgen van foute gegevens geconfronteerd worden.
Deze beperkingen waren lang onvermijdelijk en werden, afgezet tegen geboekte efficiëntiewinst, als acceptabel beschouwd. Maar nu overheidsorganisaties de ambitie hebben (zie hieronder) veel vaker elkaars gegevens gebruiken als grondstof voor nieuwe besluiten en gevolgen, en dat bovendien bij de bron te doen, wordt het belangrijk dat leveringen ook context, betwistbaarheid, reproduceerbaarheid en passende toegang ondersteunen.
De De Architectuur Digitale Overheid 2030 onderkent de belangrijke rol van data bij (proactieve) beleidsontwikkeling en dienstverlening van de overheid. Om wildgroei en kwaliteitsverlies te voorkomen, willen we die data liever vanuit een aangewezen bron hergebruiken dan (steeds) opnieuw inwinnen. Dat vraagt om de organisatie-overstijgende waarborgen voor gegevenskwaliteit en -uitwisselbaarheid waaraan onder de naam Federatief Datastelsel (FDS) wordt gewerkt.
Deze handreiking beschrijft hoe partijen in de FDS-rol van data-aanbieder hun data zodanig kunnen vastleggen en beschikbaar stellen dat die een bruikbare basis vormt voor FDS-datadiensten.
Binnen de overheid bestaan ook andere initiatieven die vernieuwing van het fundament van de overheidsinformatievoorziening bepleiten. Sommige daarvan, zoals Regelrecht zouden traditionele registers uiteindelijk overbodig kunnen maken. Chronolexografie is een manier om heel gestructureerd rechtstoestanden - oftewel “hetgeen juridisch gezien het geval is (geweest)” - vast te leggen en te reproduceren.
Ten opzichte van bovengenoemde initiatieven zijn de aanbevelingen in deze handreiking minder vergaand, ambitieus en prescriptief (we schrijven immers geen vastleggings- of verwerkingsconventies voor). Wel liggen ze in elkaars verlengde; de uitgangspunten in deze handreiking moeten ook relevant zijn voor systemen die op regelrecht- of chronolexografiegedachtengoed gefundeerde data vastleggen en beschikbaar stellen.
We streven er dus naar deze handreiking toepasbaar te laten zijn bij uiteenlopende vereisten, omstandigheden, en omgevingen. Tegelijkertijd willen we oplossingen bieden voor de hierboven beschreven problemen. Bovendien willen we aansluiten bij, en voorsorteren op overheidsbrede ontwikkelingen die de werking van registers raken. Onderstaande uitgangspunten helpen hierbij door scope te beperken en elementaire werking te beschrijven.
We kopiëren te veel gegevens zonder mechanismen om kwaliteit en actualiteit van die kopieën te waarborgen. Deze handreiking is erop gericht de noodzaak voor het maken van gegevenskopieën bij uitvoeren van publieke dienstverleningsprocessen waar dat haalbaar is weg te nemen.
We erkennen een verschil tussen formeel beschreven of informeel uitgevoerde processen en daaruit voortkomende resultaten. Een proces vertelt hoe de overheid handelt. Als resultaat daarvan ontstaat iets met betekenis of waarde. Deze handreiking gaat niet over procesautomatisering, maar beschrijft op welke manier we de resultaten daarvan zo goed mogelijk kunnen vastleggen en beschikbaar stellen.
Als het gaat om bovengenoemde resultaten, erkennen we het verschil tussen betekenis van een resultaat - dat we gevolg noemen, en communicatie daarover, waarvoor een representatie (levering) nodig is. Het verenigen van deze concepten in één artefact - bijvoorebeeld een akte - werkt ‘vormfouten’ (bijvoorbeeld het onjuist overnemen van een juiste conclusie in een besluit of databasetabel) in de hand.
Hoewel sprake is van een afhankelijkheidsrelatie - de levering is afgeleid van het gevolg - zijn ze vanuit verantwoordingsperspectief van even groot belang. Het gevolg betekenis als ‘kern’ van wat bedoeld werd, en de levering als hetgeen op basis waarvan anderen (mogelijk) hebben gehandeld.
Bij deze conceptualisatie past de metafoor van de januskop of het hoofd met twee gezichten. Janus deelt één brein - dus een gedeelde, onderling verbonden hoeveelheid kennis, met daarop twee perspectieven, ingegeven door twee paar zintuigen. Het ene paar blikt terug op een proces dat een bepaald resultaat - of gevolg opleverde, terwijl het andere paar vooruit kijkt, richting door leveringen van die gevolgen in gang gezette vervolghandelingen.
Janus(kop)
In de beeldhouwkunst en schilderkunst is een januskop een hoofd met zowel aan de voorzijde als aan de achterzijde een gezicht. Het is genoemd naar de Romeinse god Janus, die in een van zijn verschijningsvormen twee gezichten had.
Afbeeldingscredit Igor Gordeev
Janus was een Romeinse god die heerste over alle begin en overgang. Vóór hij door Jupiter tot god met twee gezichten gemaakt werd, heerste hij volgens legende als koning over Latium. Daar werd hij beschouwd als stichter van het maatschappelijke leven en van de maatschappij, die de mensen verloste uit hun barbaarse toestand en tot een ordelijk leven bracht.
Gelijktijdig erkennen van het verschil tussen, en gelijkwaardig belang van gevolg en levering, vraagt in registerarchitectuur om onderscheid tussen bijhouding en levering. Dit maakt het mogelijk om op de specifieke informatiebehoefte van bepaalde afnemers (of leveringsconsumenten) toegesneden informatieproducten te leveren.
De wens onnodige kopieën te vermijden vraagt erom beide perspectieven als bron met zelfstandig bestaansrecht te beschouwen. Binnen het register vragen ze daarom om vergelijkbare betrouwbaarheidswaarborgen.
In het voorgaande is de context beschreven. Hieronder beschrijven we de elementen waaruit het register bestaat.
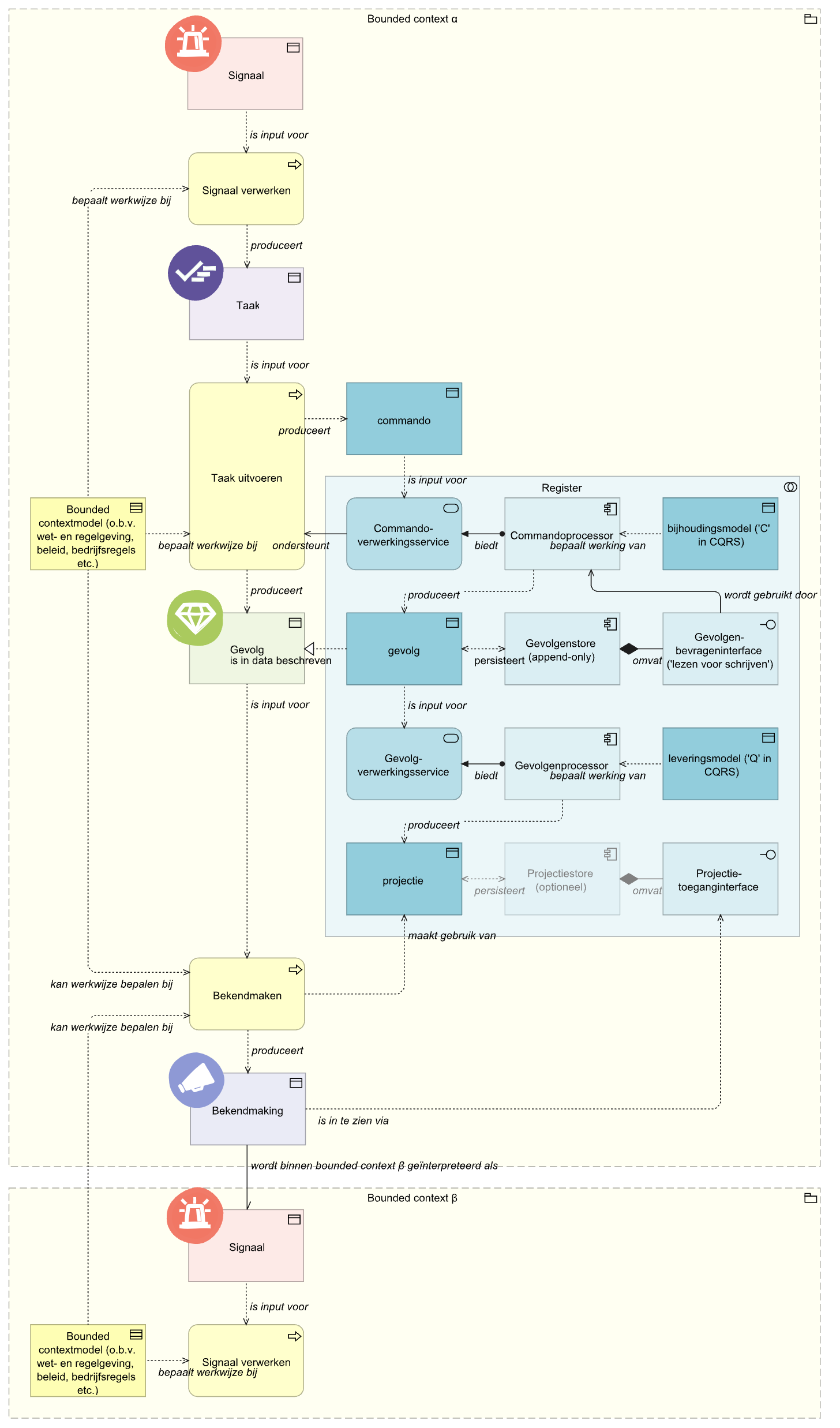
In de afbeelding hierboven zien we allereerst de eerder geïntroduceerde elementen signaal, taak, gevolg en bekendmaking terug. Deze elementen zijn geïllustreerd als bedrijfsobject.
Om op basis van het ene het opvolgende bedrijfsobject te kunnen produceren (bijvoorbeeld een gevolg op basis van een taak) zijn handelingen (bijvoorbeeld taak uitvoeren) nodig. Deze werden eerder impliciet benoemd, maar worden nu expliciet als bedrijfsprocessen opgenomen.
De wijze waarop bedrijfsprocessen worden uitgevoerd is beschreven in het model van de bounded context. De inhoud hiervan is vaak gebaseerd op andere kaders, zoals wet- en regelgeving, beleid en bedrijfs- of uitvoeringsregels. Het bindende karakter van het model wordt benadrukt door de illustratie als contract.
Het register zelf is geïllustreerd als element van het type application-collaboration om aan te geven dat het register niet per se één applicatieve component hoeft te zijn, maar ook - en misschien zelfs meestal - kan bestaan uit een samenhangende verzameling applicatiecomponenten.
De elementen die bijdragen aan de verwerking van commando’s en productie van gevolgen op basis daarvan vormen de bijhoudingskant (‘C’ in CQRS) van het register.
Het register wordt bediend door het aanbieden van commando’s. Deze data-objecten volgen altijd de taal en het model van de bounded context waarbinnen ze worden gemaakt en verwerkt.
Zowel de semantische en syntactische eisen aan commando’s als de wijze waarop die verwerkt moeten worden, zijn beschreven in het bijhoudingsmodel (data-object). Dit vormt dus het contract op basis waarvan commando’s worden verwerkt.
De Commandoverwerkingsservice (applicatieservice) controleert of aangeboden commando’s aan het contract voldoen.
Het bijhoudingsmodel en Commandoverwerkingsservice horen bij de Commandoprocessor (applicatiecomponent) die met het commando als input op basis van in het bijhoudingsmodel beschreven regels gevolgen (data-objecten) produceert.
Voor ieder bedrijfsobject van het type Gevolg dat wordt geproduceerd als resultaat van het bedrijfsproces ‘Taak uitvoeren’, wordt door het verwerken van een commando een equivalent data-object van het type gevolg geproduceerd. Dit data-object is een directe representatie van het bijbehorende bedrijfsobject. Zo registeren we (tenminste) de essentie van het overheidshandelen.
Gevolgen worden opgeslagen in de Gevolgenstore (applicatiecomponent).
De Gevolgenstore biedt toegang tot gevolgen via de Gevolgen-bevrageninterface (applicatie-interface). Deze interface wordt gebruikt door de Commandoprocessor als gegevens uit eerder vastgelegde gevolgen nodig zijn om te beoordelen welk gevolg moet worden geproduceerd.
De elementen die bijdragen aan de verwerking van gevolgen en productie van projecties op basis daarvan vormen de leveringskant (‘Q’ in CQRS) van het register.
Een gevolg dient als input voor de Gevolgenverwerkingsservice (applicatieservice).
De Gevolgenverwerkingsservice is onderdeel van de Gevolgenprocessor (applicatiecomponent) die projecties (data-objecten) produceert.
Projecties worden opgebouwd op basis van het leveringsmodel (data-object) dat beschrijft welke gegevens in welke vorm in een bepaalde projectie worden opgenomen.
Een projectie is een data-object, bedoeld om afnemers binnen en buiten ‘onze’ bounded context te informeren over wat binnen onze context is gebeurd. Een projectie kan allerlei vormen hebben: een databaserelatie, een notificatie(bericht) of een (digitaal) document.
Van het ‘setje’ Gevolgenverwerkingsservice, Gevolgenprocessor en leveringsmodel kunnen er meerdere naast elkaar bestaan. Dit betekent dat één gevolg door meerdere Gevolgenprocessoren wordt verwerkt om verschillende projecties op te bouwen.
Projecties kunnen ‘on demand’ (op aanvraag) worden gegenereerd of worden gepersisteerd. In dat laatste geval is in de vorm van een Projectiestore een extra applicatiecomponent nodig.
Toegang tot projecties wordt geleverd door de Projectietoegangsinterface (applicatie-interface).
Anders dan bij de relatie tussen Gevolg (bedrijfsobject) en gevolg (dataobject), vormt de projectie (dataobject) niet de volledige representatie van de Levering (bedrijfsobject). De projectie bestaat immers direct nadat die is geproduceerd, terwijl van een Levering pas sprake is nadat de projectie of een selectie daaruit aan iets of iemand is beschikbaar gesteld. Een Levering is daarom een voor consumptie aangeboden projectie.
Bespiegeling over projectie op basis van gevolg versus gevolg volgend op eerder gevolg
Bovenstaande laat ruimte voor discussie over de vraag in welke gevallen sprake is van een projectie op basis van een gevolg en een gevolg op basis van een eerder geproduceerd gevolg. Hiernaar kunnen we op ten minste drie manieren kijken:
- Iedere bewering die op basis van een gevolg (geautomatiseerd) binnen het register kan worden gecreëerd, beschouwen we als projectie. De binnen het register geproduceerde bewering met een ‘happened’, of gebeurtenisachtig karakter “aanschrijfvorm van persoon p1 gewijzigd in ‘mevrouw’” op basis van gevolg “geslacht van persoon p1 gewijzigd in ‘vrouw’” wordt in dit geval beschouwd als projectie.
- We beschouwen alleen representaties van een gevolg zelf, of daarvan afgeleide stand (of state-)informatie als projecties. Vervolgbeweringen met een ‘happened’-karakter beschouwen we als nieuwe gevolgen. De binnen het register geproduceerde bewering “aanschrijfvorm van persoon p1 gewijzigd in ‘mevrouw’” op basis van gevolg “geslacht van persoon p1 gewijzigd in ‘vrouw’” is in dit geval als nieuw gevolg. De op basis van hetzelfde gevolg geproduceerde standbewering “geslacht van p1 is ‘vrouw’” beschouwen we wél als projectie.
- We maken helemaal geen onderscheid tussen gevolgen en projecties. Iedere nieuwe bewering zien we als gevolg.
Het verwerken van signalen kan uiteraard ook applicatief ondersteund en eventueel geautomatiseerd worden. Dit geldt zeker als een signaal in de vorm van een notificatie wordt ontvangen. Omdat zo’n notificatie (ten opzichte van het register) veelal van buiten de ‘eigen’ bounded context afkomstig is, en vanuit het register dus geen controle bestaat over de vorm en inhoud daarvan, beschouwen we de elementen in de applicatiearchitectuur die hiervoor nodig zijn niet als onderdeel van het register. Deze elementen zijn daarom hierboven niet geïllustreerd.
{kind=link}